Projet Films à succès

L’objectif : Pour ce projet, j’ai décidé de prendre un dataset provenant du site kaggle qui fournit des données pour s’entraîner. Ce dataset comprend un fichier provenant du site Wikipédia sur les films à gros succès. Mon objectif est d’explorer ces données dans le but de comprendre quels sont les acteurs de ces films.
La Data : Les données fournies s’étendent de 1980 à aujourd’hui. On y retrouve les noms des films, leurs genres, leurs réalisateurs, leurs notations sur 10, leurs budgets et leurs revenus ainsi que d’autres informations. Afin de pouvoir analyser les données, j’ai décidé d’importer ce fichier csv sur Jupyter. Le but était de réaliser dans un premier temps une exploration des données pour réaliser une analyse sur les acteurs du succès d’un film.
Intégration dans Python: Une fois avoir lancé Anaconda et Jupyter notebook, je peux créer mon nouveau projet. Je commence par importer les librairies qui me seront nécessaires. Les quatre principales librairies que je vais utiliser sont Pandas, NumPy, Seaborn et Matplotlib. Pandas et NumPy sont très pratiques pour la manipulation et l’analyse de données de manière simple et intuitive. Pandas nous offre de son côté la possibilité de lire et écrire dans des fichiers de différents formats tels que csv, txt, xls, sql etc… Quant à NumPy, elle fournit des opérations pour le traitement de données qui nous permet de faciliter son utilisation. Seaborn et Matplotlib seront eux utilisés dans un but de visualisation des données. Cela nous permettra de construire des barres graphiques, des matrices et autres.
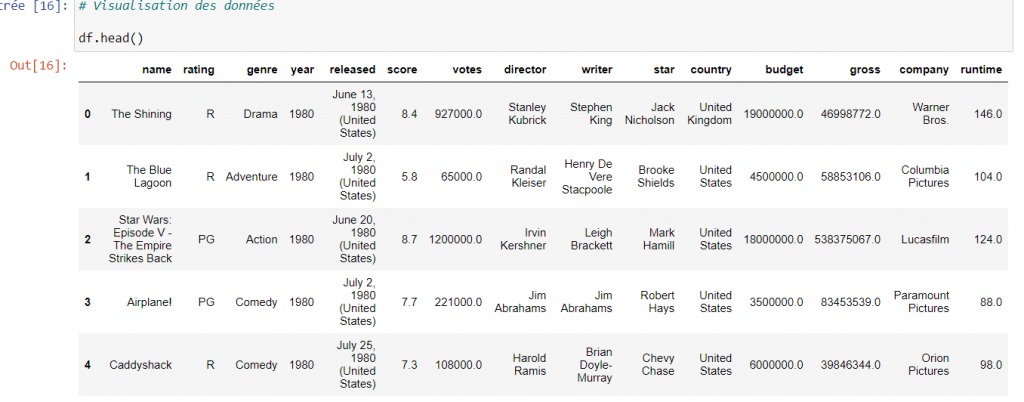
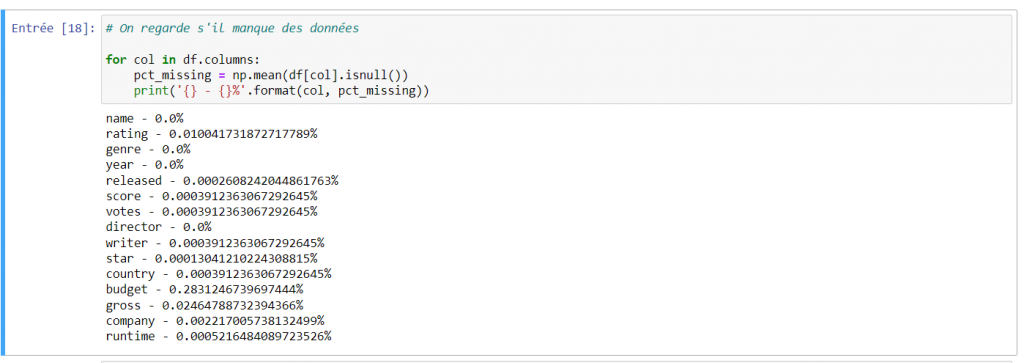
Exploration des données : Pour en savoir plus sur mon sujet, je fais apparaître les 5 premières lignes de mon fichier csv, avec un df.head(). Je note que les données sont réparties sur 15 colonnes qui comportent toutes des données intéressantes. Afin d’en apprendre un plus sur mon fichier, je cherche à savoir s’il existe des données null, manquantes qui pourraient m’induire en erreur pendant mon analyse. Ici plusieurs possibilités s’offrent à moi : je peux utiliser df.isnull().sum(), pour avoir le total de données manquantes par colonne, mais j’ai décidé d’exécuter un autre code.
for col in df.columns:
pct_missing = np.mean(df[col].isnull())
print(‘{} – {}%’.format(col, pct_missing))
En utilisant cette boucle for, je peux représenter avec précision les données manquantes par colonnes. Je me rends compte que plusieurs colonnes comportent des données null.
Cela peut être dû aux nouveaux films sortis qui n’ont pas encore dévoilé tous leurs chiffres (Avatar 2…) ou encore à certains films qui n’ont jamais partagé ces informations.
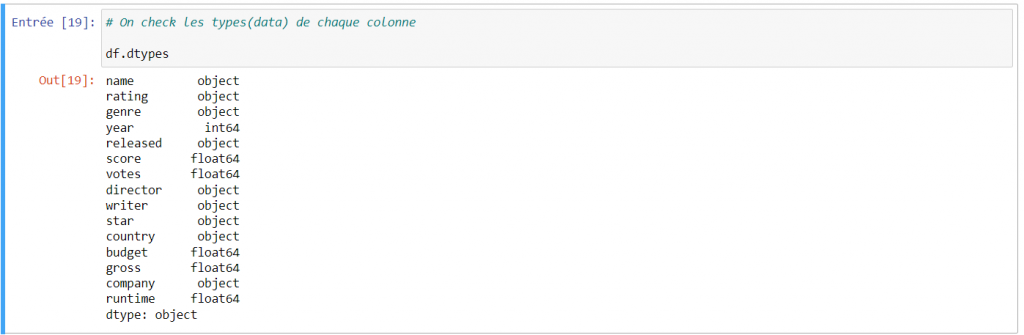
Pour continuer, j’analyse les types des données de mes colonnes afin de voir si elles sont toutes adaptées aux données. J’utilise donc df.info() ou df.dtypes() et je m’aperçois que certains types ne sont pas adaptés aux données. Les colonnes “budget” et “gross” sont par exemple en float, alors qu’elles devraient être en int64 du fait que les chiffres ont été arrondis sans décimales.

Nettoyage de données : Dans un premier temps, je commence par effacer les données manquantes avec df.dropna(). Pour continuer, je réutilise ma boucle for pour voir s’il reste des données null. Toutes les colonnes sont à 0%, je peux donc continuer. Comme dit un peu plus haut, j’avais remarqué que les colonnes “budget” et “gross” étaient en float alors qu’elles n’en avaient pas l’utilité. Je change donc leurs types de donnée avec :
df[‘budget’] = df[‘budget’].astype(‘int64’)
df[‘gross’] = df[‘gross’].astype(‘int64’)
Une fois exécuté, je peux donc afficher mon head afin de vérifier si le changement de type a bien été effectué.
Pour finir, avant de préparer mes données, il me reste à savoir s’il existe des doublons. Généralement sur des fichiers provenant de sites comme Wikipédia, il n’y en a pas mais je préfère avoir la conscience tranquille et j’exécute donc le code suivant :
df[‘company’].drop_ducplicates()
Je réalise la suppression des doublons sur les noms des studios car un film peut avoir un reboot avec le même nom mais pour un studio différent.
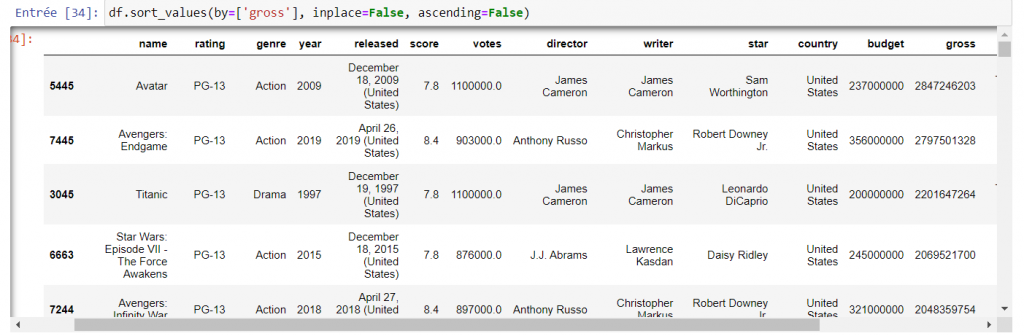
Préparation des données : Une fois mon nettoyage terminé, je cherche à comprendre quels sont les acteurs des films à succès. Dans un premier temps, j’analyse les films à plus gros succès qui ici correspondent à ceux aux meilleurs bénéfices. Je trie donc mes films par leurs recettes par ordre décroissant. De ce fait, je veux faire apparaître en haut les plus grosses recettes du cinéma. On voit bien que le top 3 est donc :
- Avatar : 2 847 246 203 euros de recettes
- Avengers Endgame :2 797 501 328 euros de recettes
- Titanic : 2 201 647 264 euros de recettes
Création des visuels :
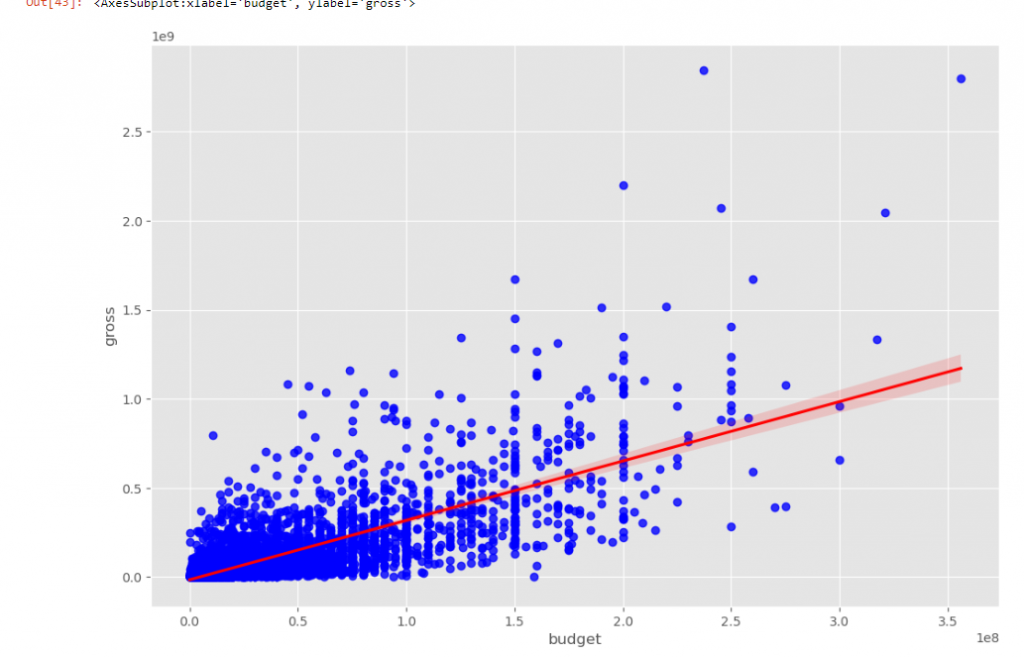
Ma première hypothèse sur les raisons de ce succès est le budget consacré à ces films. En effet, on remarque que le top 3 possède aussi les plus grosses ressources financières du cinéma. Je vais donc comparer les budgets des films aux recettes sur un nuage à points et en dessiner la courbe de tendance. Pour ça, je peux compter sur matplotlib qui va me fournir les éléments nécessaires.
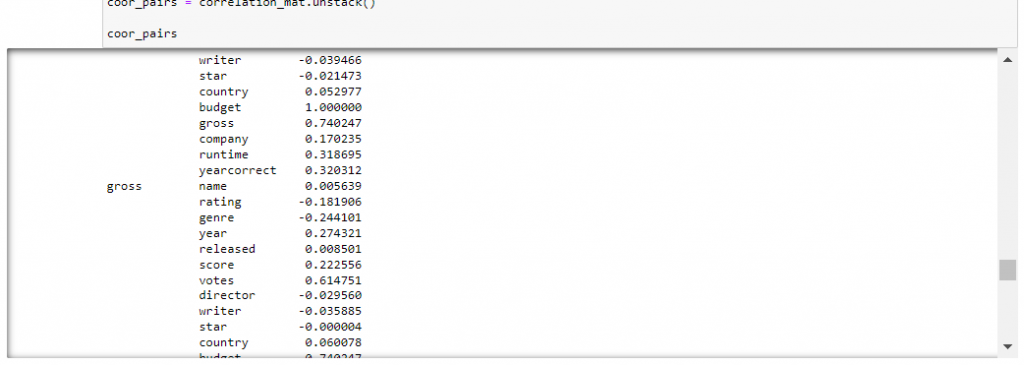
On voit bien qu’une tendance se dessine entre le succès des films et le budget qui leur est consacré. Dans un deuxième temps, afin d’avoir plus de détails sur cette corrélation, je vais analyser les ratios entre les différentes colonnes.
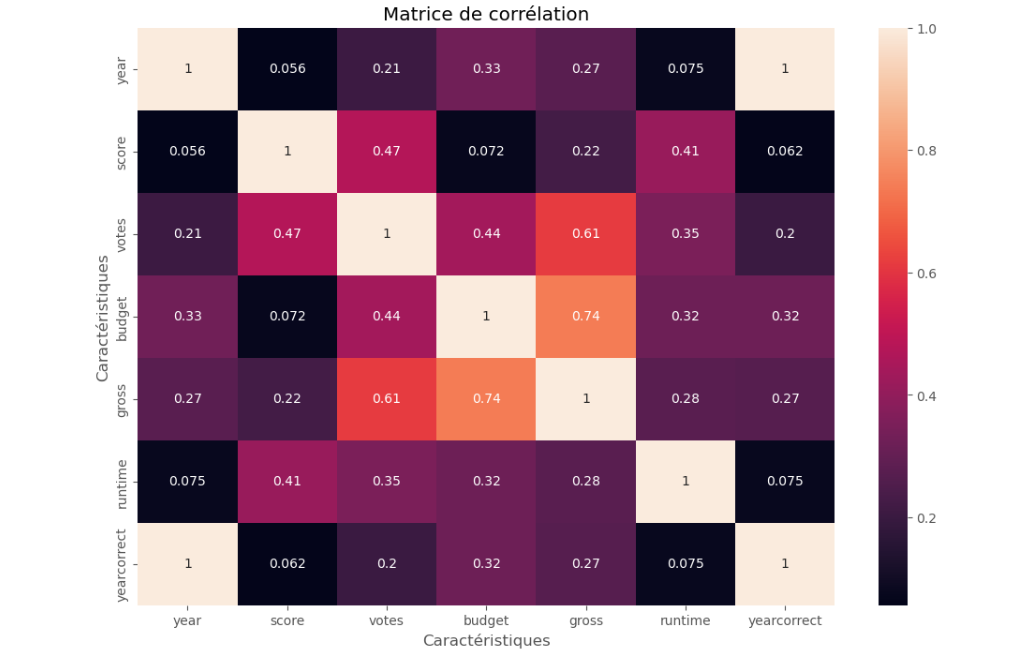
On remarque que le ratio le plus élevé est celui entre la relation budget et recettes, ce qui vérifie bien notre hypothèse.
Pour finir, je voulais vérifier une deuxième hypothèse concernant le succès des films qui serait aussi lié au nom du réalisateur ou bien du studio de production. Le problème est que ces données sont en string et donc pas comparables avec les recettes. Pour cela, je vais les numériser afin de pouvoir elles aussi les intégrer à une matrice.
J’exécute le code suivant :
df_numerized = df
for col_name in df_numerized.columns:
if(df_numerized[col_name].dtype == ‘object’):
df_numerized[col_name] = df_numerized[col_name].astype(‘category’)
df_numerized[col_name] = df_numerized[col_name].cat.codes
df_numerized
Comme on peut le voir, les données sont un peu compliquées à lire. Je vais les passer sous un autre format. On remarque alors qu’il n’existe pas de ratio élevé entre les recettes et les noms de réalisateurs de films et ceux des studios, cette hypothèse n’est donc pas valide .