L’intégration des données est une étape primordiale qui consiste à combiner des données provenant de différentes sources dans une vue unifiée. En effet, elle nous permet de regrouper les données dont nous avons besoin pour réaliser une analyse plus profonde et plus claire. La particularité de l’intégration de données, lorsqu’elle est précédée d’un data warehouse adapté, est qu’elle permet une vue d’ensemble plus facile à consommer. Ainsi en ce qui concerne les data analystes, elle constitue un élément essentiel pour l’analyse du présent et du passé.
MySQL / SQL Server
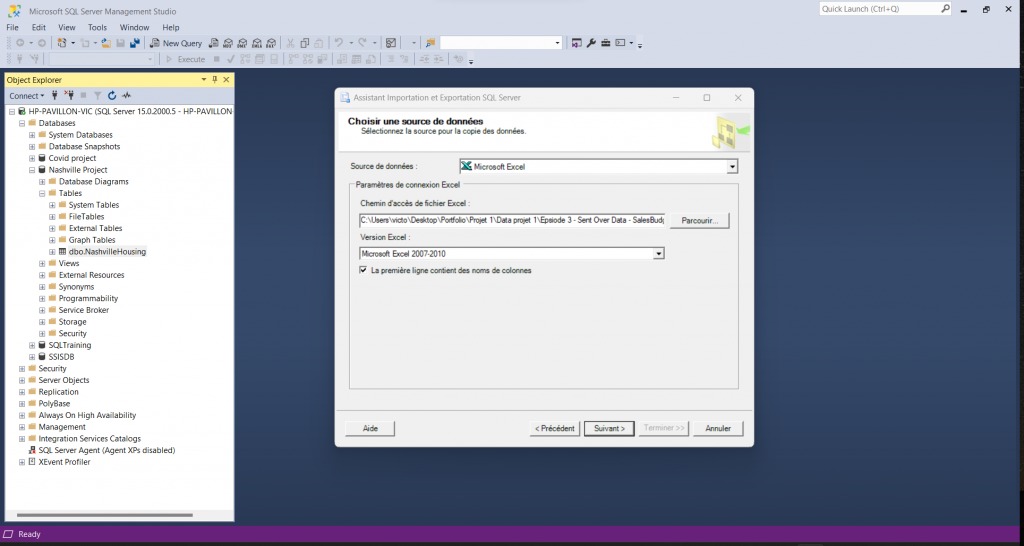
Les bases de données SQL sont assez intéressantes car en plus d’utiliser des données SQL, elles peuvent aussi, à l’aide d’un outil, intégrer des données provenant de différentes sources comme Excel, Access, fichier plat etc..
My SQL et SQL Server restent en plus un très bon moyen de préparer et nettoyer les données en vue d’analyses plus précises.
Python (Pandas / NumPy)
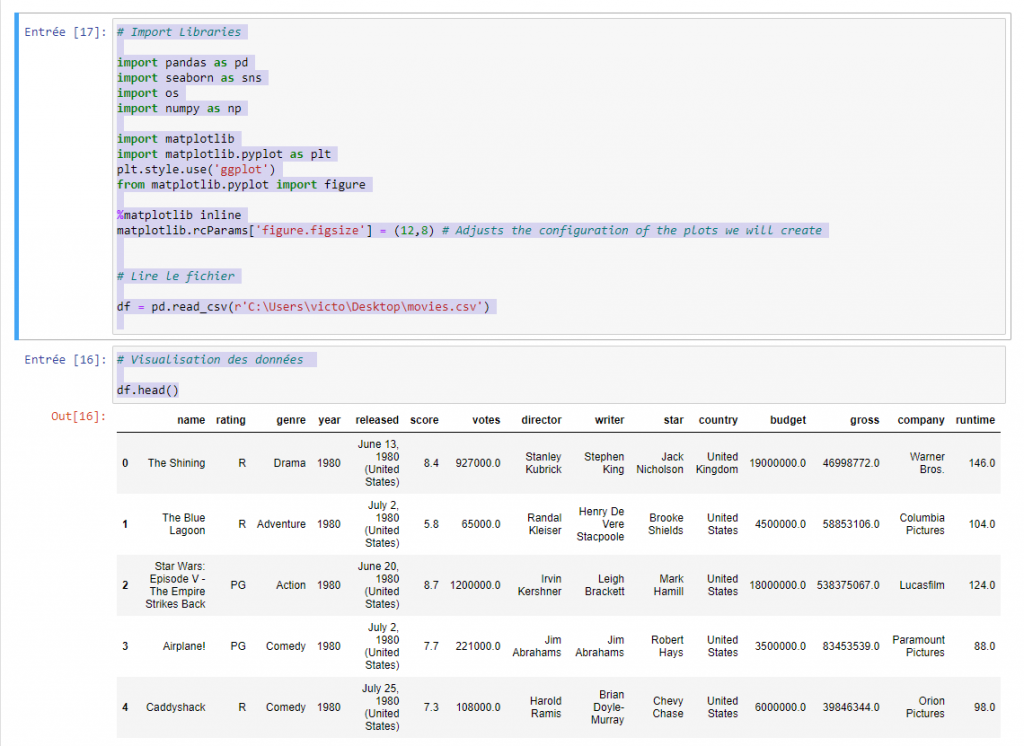
Python, et plus précisément ses bibliothèques Pandas et NumPy, sont très pratiques pour la manipulation et l’analyse de données de manière simple et intuitive. Pandas nous offre de son côté la possibilité de lire et écrire dans des fichiers de différents formats tels que csv, txt, xls, sql etc… Quant à NumPy, elle fournit des opérations pour le traitement de données qui nous permet de faciliter son utilisation.
Power Bi Querry et vue Model
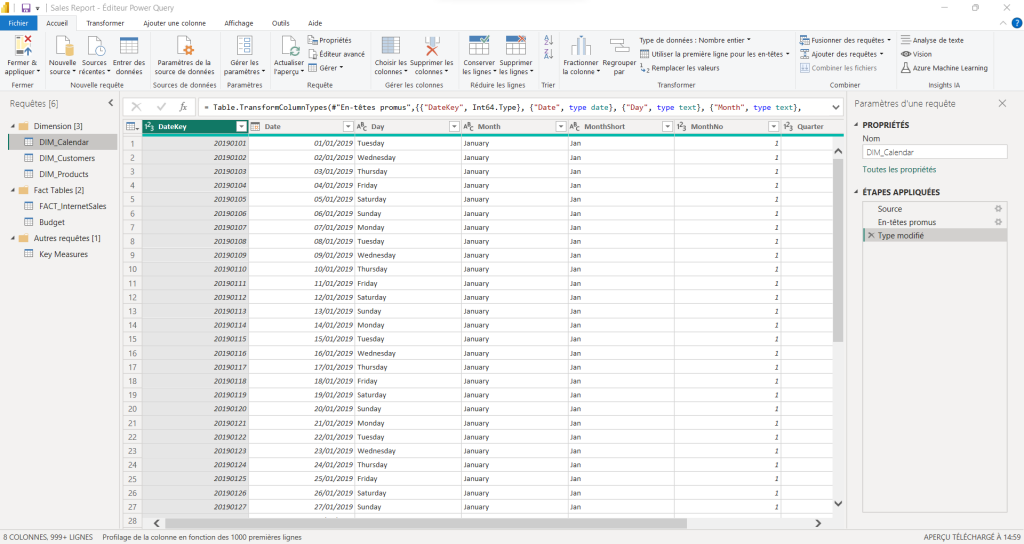
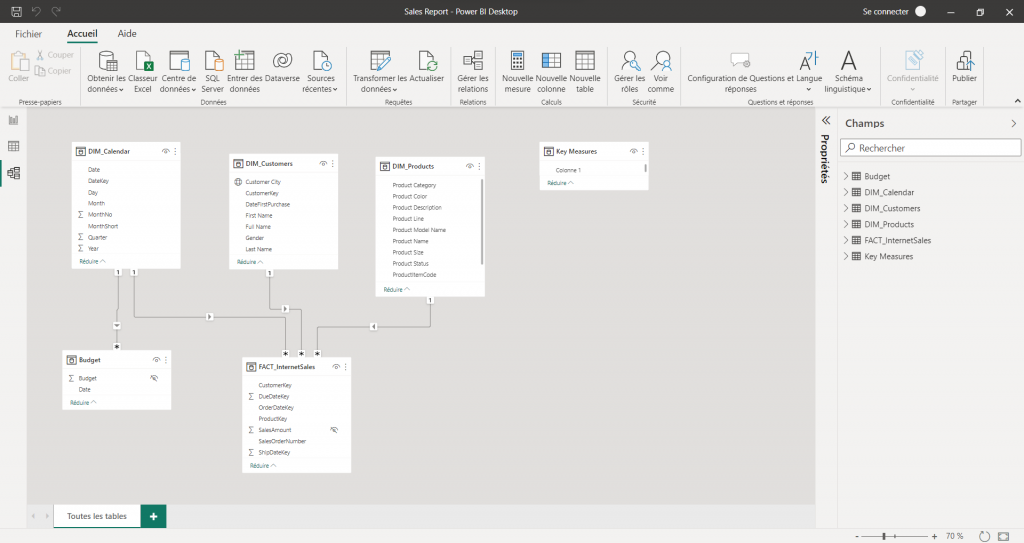
Power Bi présente un avantage par rapport à d’autres outils Bi, notamment au niveau de l’intégration de données. En effet grâce à Power Bi Query, on peut intégrer différentes sources de données qu’on va pouvoir réunir entre elles à l’aide de codes M et de la vue Modèle. Ainsi elle rend la tâche beaucoup plus simple et permet une analyse plus poussée pour des projets au sens plus large.