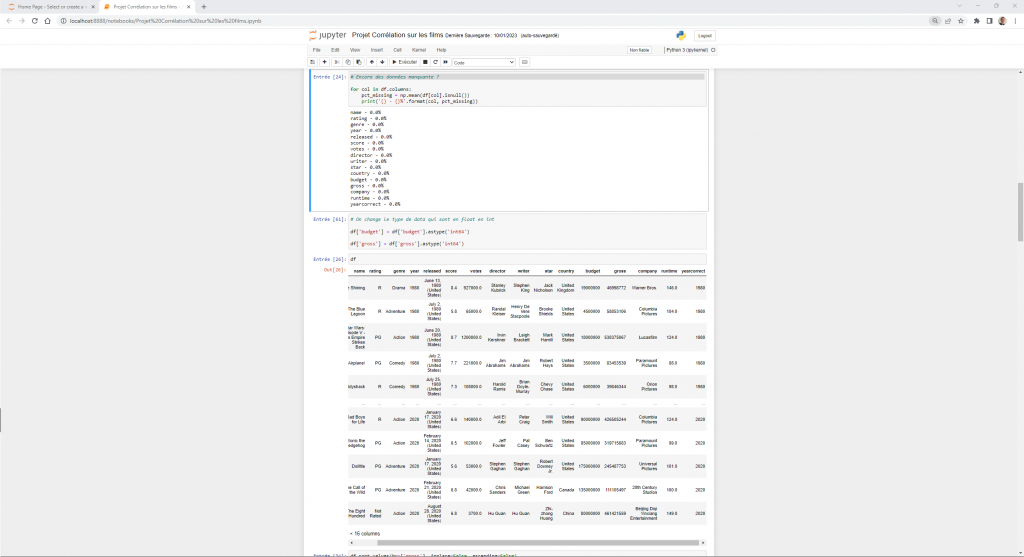
Le Data Cleaning est une étape indispensable lorsqu’on travaille avec des données. C’est pourquoi j’y ai apporté une attention particulière. Il permet de corriger et supprimer les données inexactes, changer les types, améliorer la compréhension de certaines données et donc de limiter le risque d’analyse faussée. Dans un premier temps, j’ai commencé à travailler à partir de fichiers excel et csv en utilisant les formules excel. Très vite, j’ai traité avec des bases de données SQL Server et MySQL. Dans un second temps, j’ai poursuivi mon travail avec différentes données et je me suis adapté à elles en fonction de l’outil de Dataviz à utiliser. C’est donc à travers Excel, SQL Server, MySQL, Power Querry et Python que je nettoie aujourd’hui les données que je récupère.
Franchise de vélo
Dans cet exemple, on retrouve un fichier comportant différentes informations (id, revenu, profession, niveau d’études, genre…) sur les acheteurs de vélos d’une franchise. Le but était de réaliser une étude sur le budget, le type de vélo à allouer en fonction de la cible.
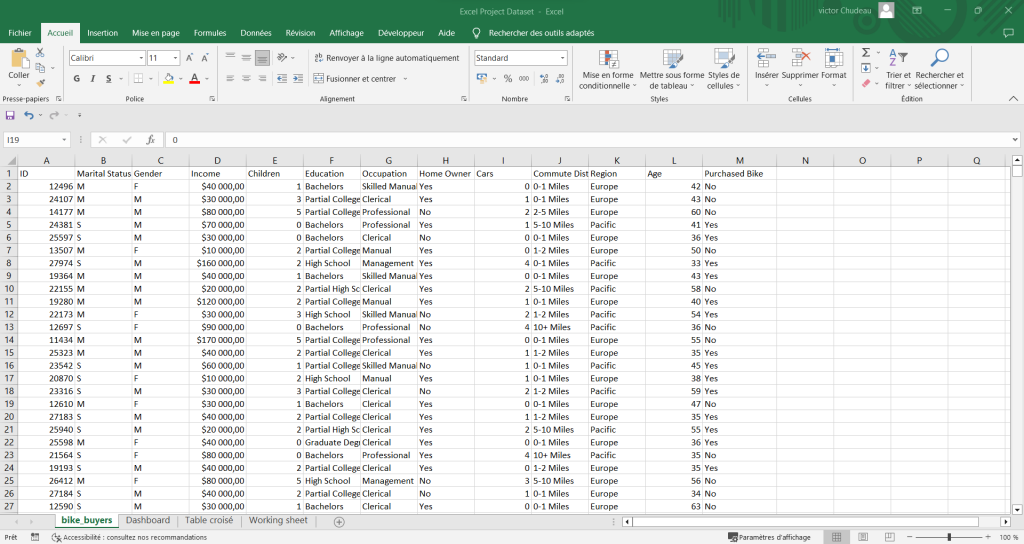
Dans le premier tableau, on peut constater directement que les colonnes “Marié statuts » et “Genre” portent à confusion. Certaines données sont identiques, le “M” de marié et le “M” de mâle, c’est pour cela que j’ai apporté une précision sur le second tableau.
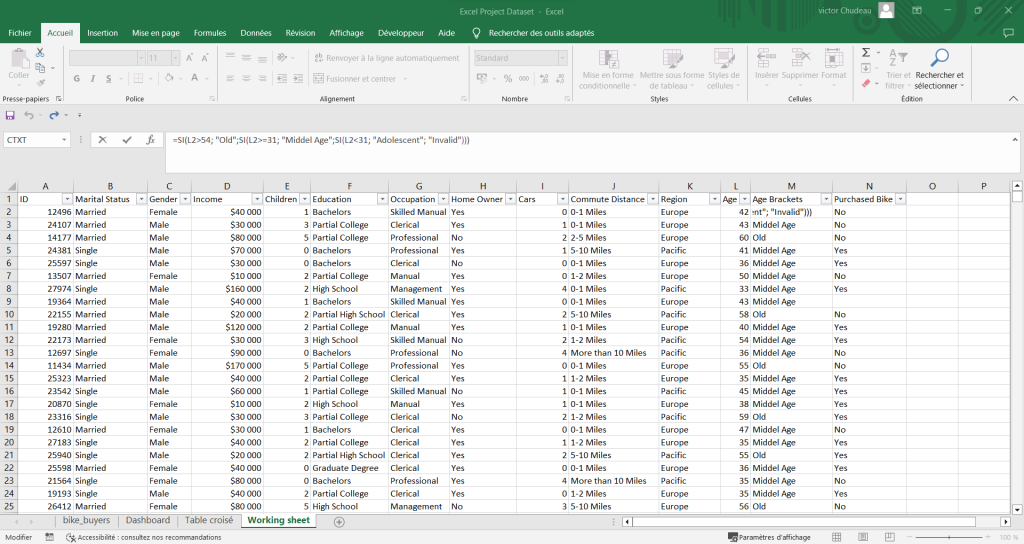
Par expérience, je sais que la rangée des âges va poser problème pour mon analyse et ma visualisation. C’est pourquoi à l’aide d’une formule SI, je crée une nouvelle colonne afin d’encadrer les âges des clients en trois champs “Adolescent”, « Middle Age”, “Old”.
Pour finir, je règle quelques détails concernant les revenus “Income” qui comportent les décimales en trop et un format de données inapproprié. Je rectifie les données “10+ Miles” en “More than 10 Miles” dans un souci de visualisation.
Agence Nashville
Dans ce second exemple, on retrouve une base de données SQL Server comportant différentes informations d’une agence immobilière sur les habitants de Nashville (Adresse, situation familiale, nom, valeur du bâtiment, âge du bâtiment…).
Dans un premier temps, j’ai analysé les différentes données qui m’ont été fournies et remarque que certaines données sont manquantes concernant les adresses en raison de la présence de deux colonnes “PropertyAdress”. Pour endiguer le problème, je réalise une jointure sur ces colonnes avec la même table pour laquelle ces valeurs sont nulles.
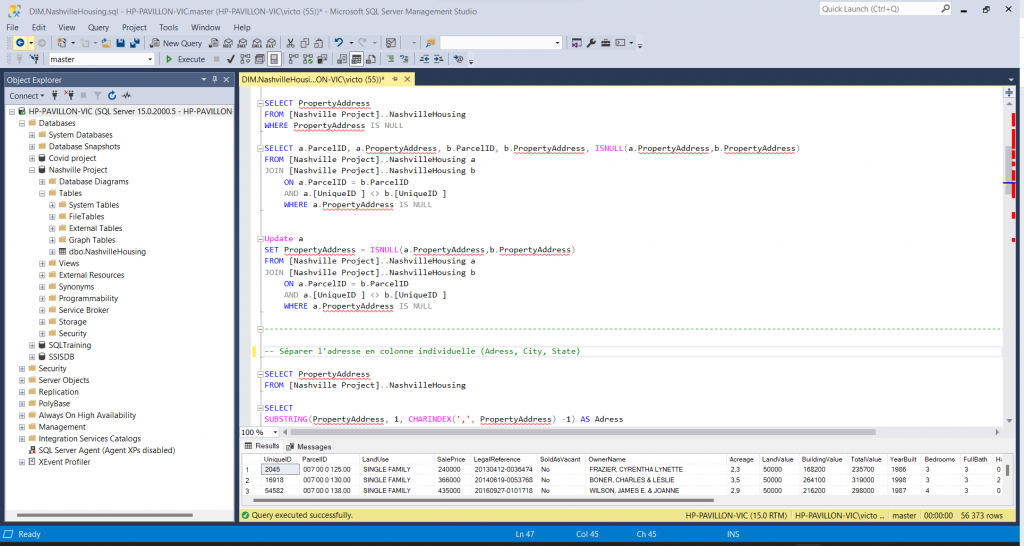
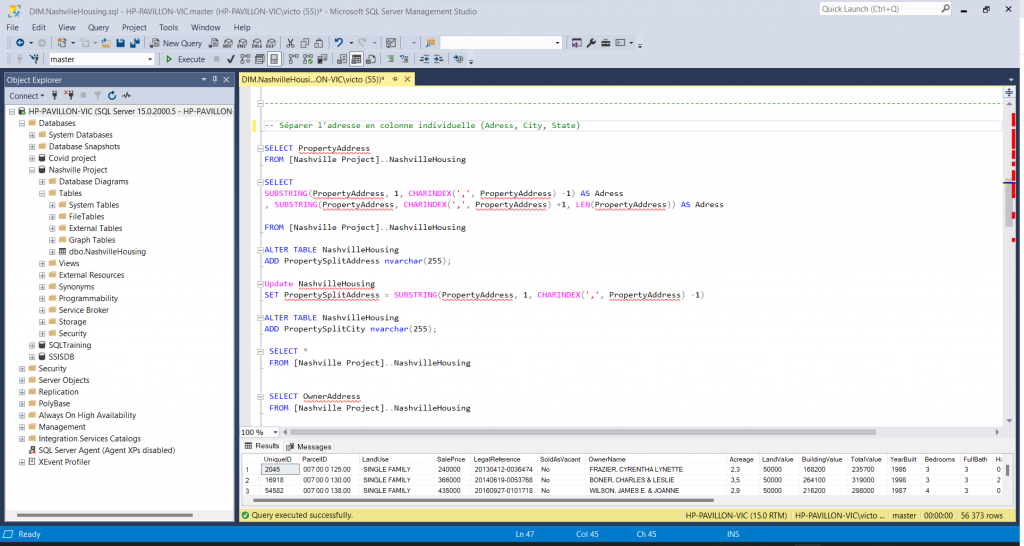
Dans un second temps, je remarque que la colonne “PropertyAdress” contient à la fois l’adresse de rue, la ville et l’état des propriétaires. Dans un souci de visualisation, je décide de les séparer dans des colonnes individuelles.
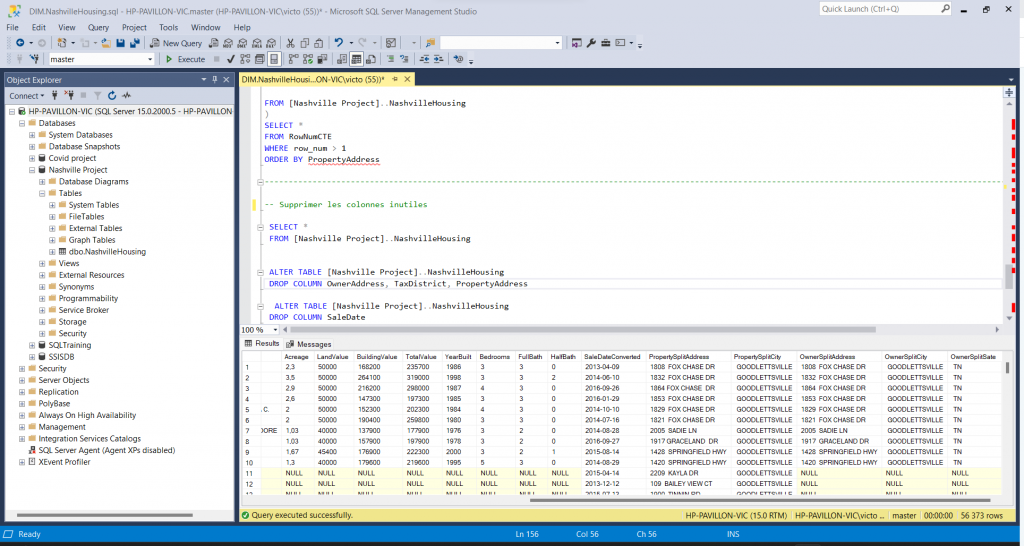
Pour finir, voici un exemple de nettoyage que j’ai réalisé sur ce fichier : j’ai tout simplement supprimé les doublons ainsi que les colonnes devenues inutiles.
Pour ce fichier, je n’ai pas détaillé tous les changements apportés mais vous pouvez retrouver tous les détails ci-dessous.
Films à succès
Dans ce dernier exemple, on retrouve un nettoyage de données à travers python (Jupyter). Le fichier qui est un csv regroupe un certain nombre d’informations sur les plus gros succès de films (nom, genre, recettes, coûts, réalisateur….). Le but était de réaliser une étude sur les acteurs d’un film à succès.
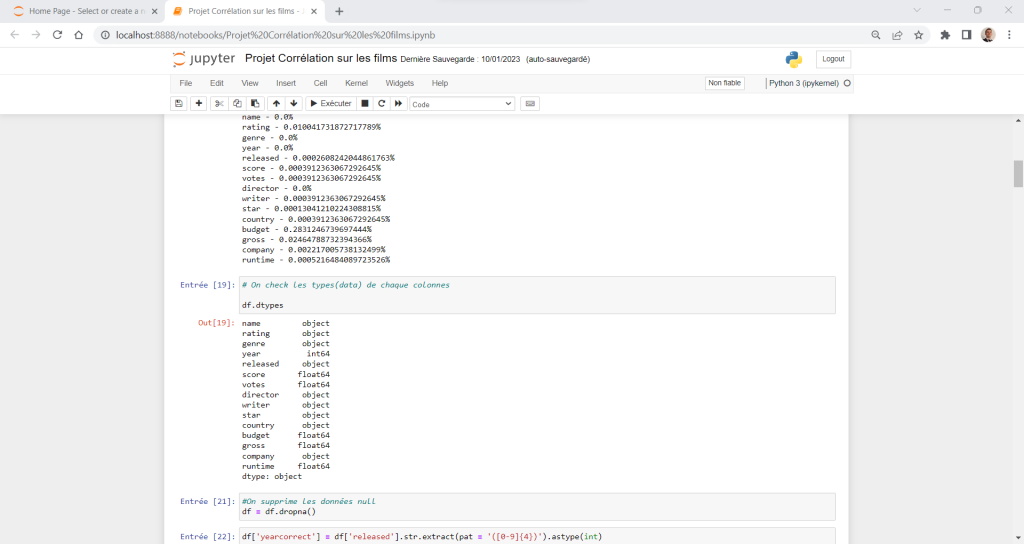
Dans un premier temps, j’analyse les colonnes afin de me rendre compte des types de données et de celles manquantes.
Puis je commence à effacer les données manquantes car comme on peut le voir, plusieurs sont en attente en raison des dernières sorties (Avatar 2….).
Dans un second temps, je me rends compte que la date de sortie des films est sous un format différent avec le jour, la date, l’année et le pays. Toujours dans un souci d’analyse, je décide de séparer l’année du reste, dans une autre colonne appelée “yearcorrect”.
Dans un troisième temps, je modifie les données “budget” et “gross” qui sont inutilement en float. Je les change en int64 et je trie mes données selon leurs recettes.